
Varians
Varians er et meget anvendeligt begreb i deskriptiv statistik, inferential statistik og sandsynlighedsregning.
Hvad er varians?
Inden for deskriptiv statistik er det korrekte navn faktisk ’empirisk varians’. Varians (alene) knytter sig i stedet til den inferentiale statistik. Glemmer man ’empirisk’, når man arbejder med deskriptiv statistik, kan varians dog godt stå alene betydningsmæssigt.
Varians er et mål for hvor meget observationerne i observationssættet i gennemsnit afviger fra middeltallet (middelværdien). Varians er en af de såkaldte statistiske deskriptorer.
For ugrupperede observationer har varians én betydning og for grupperede observationer, hvor observationerne er inddelt i intervaller, en anden.
Til at begynde med behandles varians for ugrupperede observationer. Den sidste del af artiklen omhandler varians for de grupperede observationer.
Varians må ikke forveksles med variationsbredde, da disse to statistiske deskriptorer er meget forskellige i betydning og anvendelse, trods deres enslydende navne.
Varians og spredning er knyttet tæt sammen, da kvadratroden af variansen er lig med spredning. Læs mere om spredning (standardsafvigelse).
Som beskrevet ovenfor knytter varians sig tættere sammen med middeltal og observationssættets middeltendens, hvorimod variationsbredde siger noget om observationssættets endepunkter. Se endvidere artiklen Boksplot.
Varians er IKKE en af de statistiske deskriptorer, der blot kan aflæses. Men varians for ugrupperede observationssæt kan nemt beregnes ved hjælp af nedenstående formel:
Varians-formel
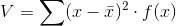
V er varians
x er de enkelte observationer
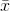 er middeltal
er middeltal
f(x) er frekvensen af de enkelte observationer
Dette lyder måske sværere og mere kompliceret end det i virkeligheden er. Lad os se på et par eksempler, da de kan være med til at øge overskueligheden og forståelsen for varians.
Eksempel 1
En person rejser ofte frem og tilbage mellem Århus og København. Dette ordnede observationssæt viser prisen på de seneste 10 ture:
160, 160, 160, 160, 160, 250, 250, 404, 404, 404
Pris Hyppighed Frekvens
160 5 0,50 = 50%
250 2 0,20 = 20%
404 3 0,30 = 30%
Middeltal beregnes til:
= 
Inden man kan udregne varians, skal man både kende frekvens og middeltal. Når de to statistiske deskriptorer er beregnet, kan varians bestemmes:

Dermed er varians for prisen på ture mellem Århus og København lig med 11163,36. Ikke en størrelse der siger én meget, men tallet giver straks mere mening, når man taler om standardafvigelse (spredning).
Eksempel 2
Her benyttes eksempel 3 fra artiklen Middeltal til at udregne varians for det samme observationssæt.
To elever får følgende fordeling af karakterer i 20 eksaminer, angivet med hyppighed og frekvens:
Karakter Elev 1 Elev 2
4: 2 = 0,10 8 = 0,40
7: 8 = 0,40 2 = 0,10
10: 8 = 0,40 2 = 0,10
12: 2 = 0,10 8 = 0,40
Sum: N = 20 N = 20
For elev 1 har vi udregnet at middeltal = 8,4, og for elev 2 er middeltal = 8,1.
Derefter kan varians udregnes med følgende formlen ovenfor:


Variansen viser, at der er stor forskel på de to elever, en forskel der yderligere uddybes i artiklen Standardafvigelse.
Varians for grupperede observationer
Varians for grupperede observationer er lidt anderledes defineret end for ugrupperede observationer.
For grupperede observationer antager man, at de enkelte observationer ligger jævnt fordelt i intervallet. Man fastsætter et intervalmidtpunkt, x_ midt, se artiklen om Middeltal for nærmere forklaring.
Beregning af varians for grupperede observationer foregår næsten på samme måde som for ugrupperede observationer. Blot skal x_ midt og f(I) indsættes, da det er intervaller der danner grundlag for beregningen af varians. Formlen ser således ud:
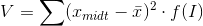
V er variansen
x_midt er det fastsatte intervalmidtpunkt
er middeltallet
f(I) er intervalfrekvensen
Eksempel 3
Fra eksempel 4 i artiklen Middeltal kender vi følgende datasæt om aldersfordelingen af 25 børn i alderen 0 - 15 år:
| Aldersinterval, år | Intervalhyppighed | Intervalfrekvens f((I) |
| 0 - 3 | 4 | 0,16 = 16 % |
| 4 - 6 | 5 | 0,20 = 20 % |
| 7 - 10 | 10 | 0,40 = 40 % |
| 11 - 15 | 6 | 0,24 = 24 % |
Derefter fastsættes et intervalmidtpunkt som en alder midt i intervallet:
0 - 3 år: x_midt = 1,5
4 - 6 år: x_midt = 5
7 - 10 år: x_midt = 8,5
11 - 15 år: x_midt = 13
Middeltallet er beregnet til = 7,76
Variansen kan nu beregnes:

Varians siger i sig selv ikke så meget, men når man tager kvadratroden af V, og udregner standardafvigelse (spredning), giver det en mere håndgribelig information.