
Matematik
Paremterestimationer
Jeg ser på statistik og har lidt svært ved at forstå notation, terminologi og generelt det intuitive forståelse bag paremterestimationer. Mere konkret har jeg svært ved at se hvad forholdet er mellem paremterestimator 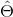 og paramter
og paramter 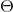 . Skal her blive betragtet som et udfald en stokastisk variabel?
. Skal her blive betragtet som et udfald en stokastisk variabel?
Eksempler vil muligvis gøre underværker.
Tak :)
Svar #1
08. maj 2015 af aaaaaz (Slettet)
... jeg har gennemgået elementær sandsynlighedsregning på Uni.
Svar #2
08. maj 2015 af peter lind
Skal [\Theta] her blive betragtet som et udfald en stokastisk variabel? ja
Det simpleste du kan komme ud for er et ja/nej mulighed som for eksempel, hvor stor en andel af den danske befolkning er blåøjet. Parameteren er andelen af blåøjet i Danmark Estimatoren er her andel af blå øjne i en tilfældig udvalgt gruppe. Den estimerede parameter er så det konkrete resultat af en sådan måling.
Svar #3
08. maj 2015 af Krable (Slettet)
Nu har du ikke forklaret din notation, så jeg prøver at forklarer det ud fra hvad jeg tror du spørger om. Hvis det er noget andet du er interesseret i må du sige det.
Altså 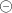 beskriver mængden af alle værdier din parameter kan antage. .f eks hvis du har
beskriver mængden af alle værdier din parameter kan antage. .f eks hvis du har 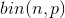 vil
vil ![p \in \circleddash=[0,1]](https://media.studieportalen.dk/images/equations/HumoLl_cLokBwjtlo6--wA==.gif) . Jeg vil forklarer forståelsen af
. Jeg vil forklarer forståelsen af 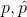 ud fra binomial fordelingen da den er simplest.
ud fra binomial fordelingen da den er simplest.
Betragt likelihoodfunktionen
![L_x : \circleddash \rightarrow [0,1] \\ L_x(p)= \binom{x}{n} p^x(1-p)^{n-x}, \quad p \in \circleddash](https://media.studieportalen.dk/images/equations/HbAzf4QupUYFfYvlEJvyXQ==.gif)
Den er det samme som sandsyngligheds funktionen vi ser nu bare p som variable og ikke x. Du vil så gerne finde værdien af den estimeret parameter 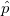 . Altså den parameter der gør din data mest sandsynlig. dvs opfylder
. Altså den parameter der gør din data mest sandsynlig. dvs opfylder
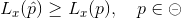 .
.
Dvs. operationen "Hat" er altså altid et estimat. Det kan vises at 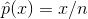 hvilket ikke er særlig overraskende.
hvilket ikke er særlig overraskende.
Svar #4
08. maj 2015 af aaaaaz (Slettet)
Tak for inputs. Sådan som jeg forstå det vi det give mening at konkludere:
![E[\Theta ]=\hat{\Theta }](https://media.studieportalen.dk/images/equations/8xgXd434P_XOb2XxmUxmCQ==.gif) .
.
Svar #5
08. maj 2015 af aaaaaz (Slettet)
Lad os betragte følgende eksmpel. Et hold bestående af 9 elever har følgende karakterer
02: 1 elev
4: 2 elerver
7: 3 elever
10: 2 elever
12: 1 elev
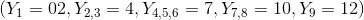
Gennemsnittet er så
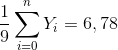
Hvordan kan jeg inddrage teorien om estimationer ind over her og beregne en og  ? :)
? :)
#4Tak for inputs. Sådan som jeg forstå det vi det give mening at konkludere:
Det giver ikke mening. Hvad du siger her er at vores forventede værdi af vores parameter er hvad vi har estimeret. Men hvis vores estimat er dårligt (parametriser fx en ternings udfald og find et estimat med kun to terningekast), så går ovenstående jo helt galt!
Derimod da 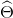 er en (oftest maksimum likelihood) estimator af , må det være fornuftigt at have at
er en (oftest maksimum likelihood) estimator af , må det være fornuftigt at have at
![E\big[\widehat \Theta\big] = \Theta](https://media.studieportalen.dk/images/equations/PtA71xhNMSmbK6_rIJiOsw==.gif)
hvis estimatoren, , er central. Det er dog mere et krav vi oftest stiller vores estimator end noget vi er sikre på. Hvis estimatoren ikke er central, vil der i det lange løb ske det at vi gætter ved siden af. Derfor er ovenstående en god egenskab ved en estimator.
#5Lad os betragte følgende eksmpel. Et hold bestående af 9 elever har følgende karakterer
02: 1 elev
4: 2 elerver
7: 3 elever
10: 2 elever
12: 1 elev
Gennemsnittet er så
Hvordan kan jeg inddrage teorien om estimationer ind over her og beregne en
Så hvad du siger her er at du prøver at finde den forventede værdi:
![E\bigg[\sum_{i = 0}^n Y_i\bigg]](https://media.studieportalen.dk/images/equations/a9SewGCffMtMMWejy6vTHQ==.gif)
Hvis vi parametriserer ovenstående har vi altså at vi ønsker at finde middelværdisparameteren
![\mu = E_\mu[X]](https://media.studieportalen.dk/images/equations/rEPHYeu_oFnXycQtrA3z_g==.gif)
hvor 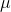 er den sande parameter.
er den sande parameter.
Med dine observationer kan vi finde et estimat for parameteren, dvs. vi vil finde
![\widehat \mu = E\bigg[\sum_{i = 0}^n Y_i\bigg] = Y_0\, p_0 + Y_1\, p_1 + \ldots Y_n \, p_n \quad \quad \color{blue}(1)](https://media.studieportalen.dk/images/equations/sNBnCfYevviJRlTZESKZsQ==.gif)
hvor 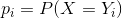 er sandsynligheden for at få udfaldet
er sandsynligheden for at få udfaldet 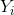 . Med antagelsen om at der er lige stor sandsynlighed for de forskellige udfald, bliver dette dog netop bare gennemsnittet:
. Med antagelsen om at der er lige stor sandsynlighed for de forskellige udfald, bliver dette dog netop bare gennemsnittet:
![\widehat \mu = E\bigg[\sum_{i = 0}^n Y_i\bigg] = \frac 1n \sum_{i = 0}^n Y_i](https://media.studieportalen.dk/images/equations/1JLfviE3XXT8PzBKVx-c0w==.gif)
men ovenstående, 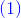 , kunne gælde også for skæve karakterfordelinger.
, kunne gælde også for skæve karakterfordelinger.
Ved de store tals lov har vi at
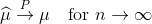
altså med nok observationer (uendeligt mange) vil vi ramme den rigtige parameter.

Her er fx et eksempel på hvordan de store tals lovs indvirkning på middelværdiestimatoren for terningekast.
Svar #10
10. maj 2015 af aaaaaz (Slettet)
Bestemt ikke. Jeg fik besvaret en række opgaver udfra dine forklaringer. Så tak :)
Skriv et svar til: Paremterestimationer
Du skal være logget ind, for at skrive et svar til dette spørgsmål. Klik her for at logge ind.
Har du ikke en bruger på Studieportalen.dk?
Klik her for at oprette en bruger.